把几年前的珍藏拿出来了喵🥰🥰
数据结构痴怎么能不学自动机?
这篇拖了很久才写,主要是对border理论不熟悉,还是想着写点真正理解后再产出的内容,一味地当复读机也没什么意义。
概述 初学字符串算法时,我们学习了Manacher算法,能够以 $O(n)$ 的复杂度求解每个字符为中心的最长回文半径。但对于更高级的问题,例如本质不同回文子串的个数等,Manacher就显得无能为力了。正如子串问题有强大的后缀自动机来处理,回文子串问题也有一个扩展性极强的自动机,那就是今天的主角,回文自动机(Palindromic Automation),又名回文树、高效扩展表示树(Efficient Extended Representation Tree,EER Tree)。
和其他自动机一样,回文自动机的每个节点表示一种状态,每条边表示转移函数。回文自动机比较特殊的一点是,它接受的是回文子串的中心及右半部分,而不是整个回文串。由于回文串分为奇回文串和偶回文串,相对应地,回文自动机的初始状态也有两个,我们下文称之为奇根和偶根。回文自动机在通常意义上的实现可以看做两棵树组成的森林,一棵维护所有奇回文串的状态,一棵维护所有偶回文串的状态。
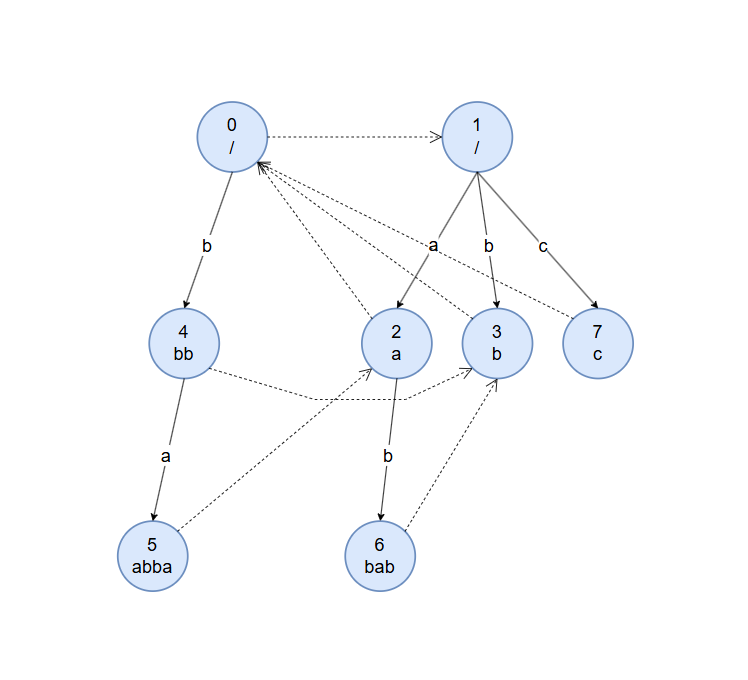
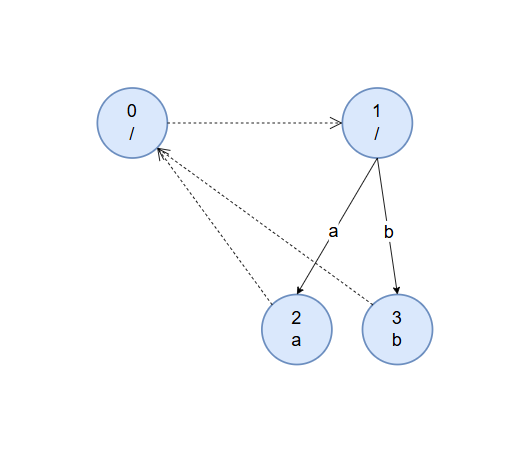
下面是字符串 $abbabc$ 对应的回文自动机结构示意图。图上实线边为转移边,虚线边为回退边,节点中数字为节点对应的编号,下方为状态对应的回文串。与后缀自动机不同,回文自动机每个状态只对应唯一一个回文串。可以通过数学归纳法证明,除去初始状态,回文自动机最多只有 $|S|$ 个节点。
构建过程 和KMP、AC自动机、后缀自动机类似,回文自动机也有后缀链接(又称 fail 指针,失配指针等)的概念,即示意图中的虚线边。回文自动机的 fail 指针指向其最长回文后缀对应的状态。
我们同时需要维护每个状态对应的回文串的长度 $len$ 。这个信息可以帮助我们构建回文自动机,而维护这个信息是平凡的。
由于维护的全部都是回文子串,所以其回文后缀同时也是回文前缀。
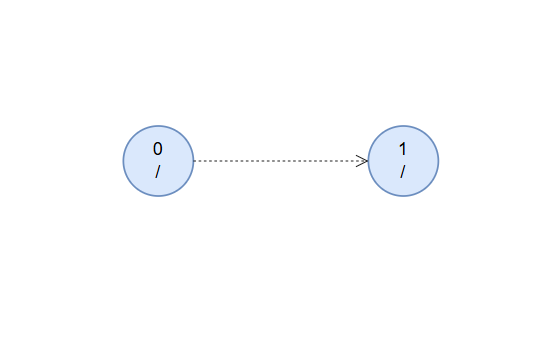
初始状态下,我们让偶根的 fail 指针指向奇根。我们无需关心奇根的 fail 指针,因为任何长度为 $1$ 的字符串均为回文串,因此奇根永远不会失配。出于方便,我们定义偶根对应状态的长度为 $0$ ,奇根对应状态的长度为 $-1$ 。初始状态如下图所示:
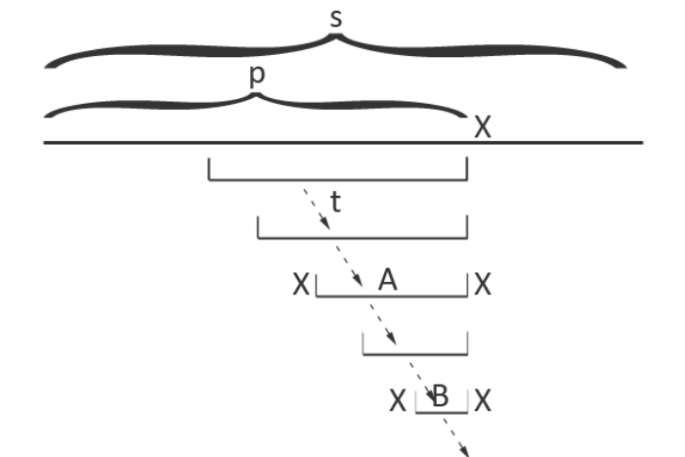
考虑构建好前 $i - 1$ 个字符的回文自动机后,在此基础上添加位置为 $i$ 的字符。我们每次从上一个字符结尾的最长回文子串对应的节点开始,沿着 fail 指针走,直到找到一个节点满足 $s[i]=s[i-len-1]$,即这个节点对应回文串开头的前一个字符与待添加字符相同。如下图,我们待添加的字符是 X ,不断沿着 fail 指针跳跃,直到串A对应的节点 $u$ 停止。如果这个节点没有新字符对应的转移边,则建新节点 $v$,将转移边指向新字符,维护节点对应子串长度 $len[v]=len[u]+2$ 。同时我们还需要维护新节点的 fail 指针,构建方式类似,从节点 $u$ 的 fail 指针指向的节点开始继续寻找,直到再找到某个节点对应子串开头的前一个字符与待添加字符相同,将新节点的 fail 指针指向这个节点向新字符的转移边对应的节点即可。如果始终没有匹配成功,则将 fail 指针指向长度为 $0$ 的偶根,其显然是所有非空子串的后缀。(这个操作无需显式维护,因为无法匹配时必定停在奇根,此时奇根到新字符的转移边没有建立,所以会自动指向偶根。)
始终无法匹配时,为什么不将 fail 指针指向奇根?
考虑构建 $aa$ 的回文自动机。已插入第一个 $a$ ,现在继续插入第二个 $a$ 。如果把 fail 指针指向奇根,那么显然新插入 $a$ 后不会创建新节点。但显然会新增回文子串 $aa$ ,故应当将 fail 指针指向偶根。
回文自动机构建代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 struct PAM { int fa[N], ch[N][26 ], len[N], d[N], idx, last; int s[N]; void init () fa[0 ] = 1 ; len[1 ] = -1 ; idx = 1 ; last = 0 ; } int get_fail (int u, int i) while (i - len[u] - 1 <= 0 || s[i - len[u] - 1 ] != s[i]) { u = fa[u]; } return u; } void insert (int c, int i) int u = get_fail (last, i); if (!ch[u][c]) { int v = ++idx; fa[v] = ch[get_fail (fa[u], i)][c]; ch[u][c] = v; len[v] = len[u] + 2 ; d[v] = d[fa[v]] + 1 ; } last = ch[u][c]; } };
具体代码实现中,注意需要先维护 fail 指针再建转移边,否则 fail 指针会产生自环。
明白了原理,现在模拟一下回文自动机构建的过程。这里以字符串 $abbabc$ 为例,逐步演示回文自动机构建过程。强烈建议读者理解构建过程后自行模拟一遍,能够极大地帮助理解和记忆算法细节。
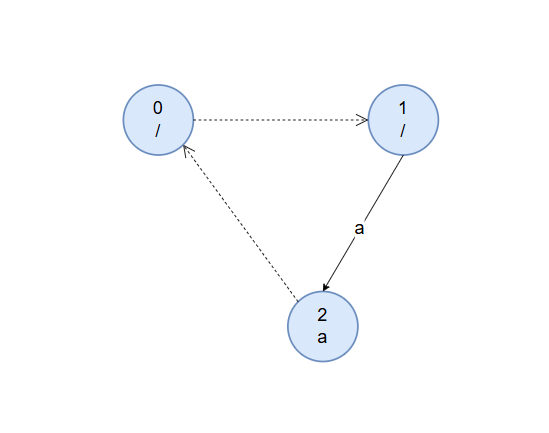
我们加入第一个字符 $a$ 。初始时认为先前最长回文子串的节点就是偶根,理由和上方类似,其为所有非空子串的后缀。跳到奇根后满足 $s[i]=s[i-len[u]-1]$ ,其字符 $a$ 转移边未指向节点,建新节点 $2$ ,奇根的字符 $a$ 转移边指向节点 $2$,同时节点 $2$ 的 fail 指针指向偶根。
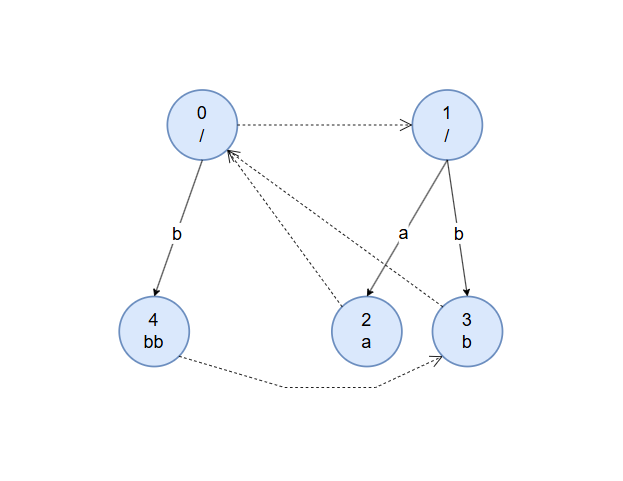
加入第二个字符 $b$ 。从节点 $2$ 开始匹配,直到奇根才满足 $s[i]=s[i-len[u]-1]$ ,其字符 $b$ 转移边未指向节点,建新节点 $3$ ,奇根的字符 $b$ 转移边指向节点 $3$,同时节点 $3$ 的 fail 指针指向偶根。
加入第三个字符 $b$ 。从节点 $3$ 开始匹配,到偶根满足 $s[i]=s[i-len[u]-1]$ ,其字符 $b$ 转移边未指向节点,建新节点 $4$ ,偶根的字符 $b$ 转移边指向节点 $4$ ,同时从 $fa[0]$ 开始继续匹配,奇根对应转移边已有节点,节点 $4$ 的 fail 指针指向节点 $3$ 。
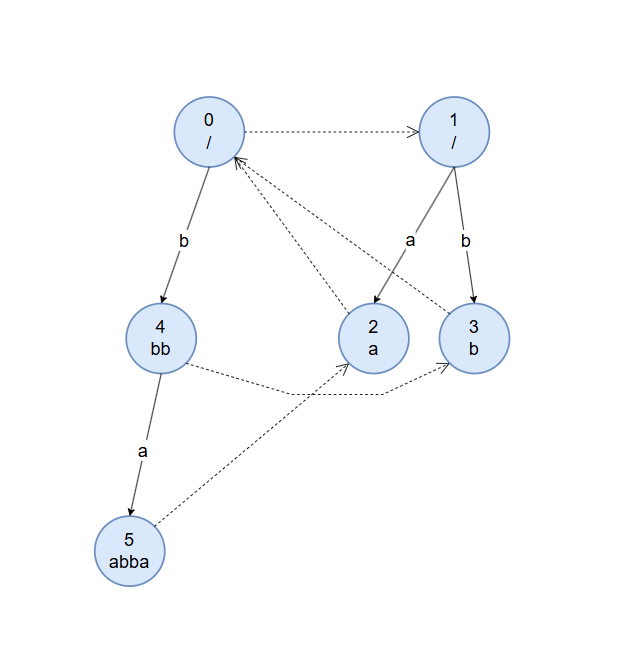
加入第四个字符 $a$ 。从节点 $4$ 开始匹配,直接满足 $s[i]=s[i-len[u]-1]$ ,其字符 $a$ 转移边未指向节点,建新节点 $5$ ,节点 $4$ 的字符 $a$ 转移边指向节点 $5$ ,同时从 $fa[4]$ 开始继续匹配,一直到奇根,奇根对应转移边已有节点,节点 $5$ 的 fail 指针指向节点 $2$ 。
加入第五个字符 $b$ 。从节点 $5$ 开始匹配,到节点 $2$ 满足 $s[i]=s[i-len[u]-1]$ ,其字符 $b$ 转移边未指向节点,建新节点 $6$ ,节点 $2$ 的字符 $a$ 转移边指向节点 $6$ ,同时从 $fa[2]$ 开始继续匹配,一直到奇根,奇根对应转移边已有节点,节点 $6$ 的 fail 指针指向节点 $3$ 。
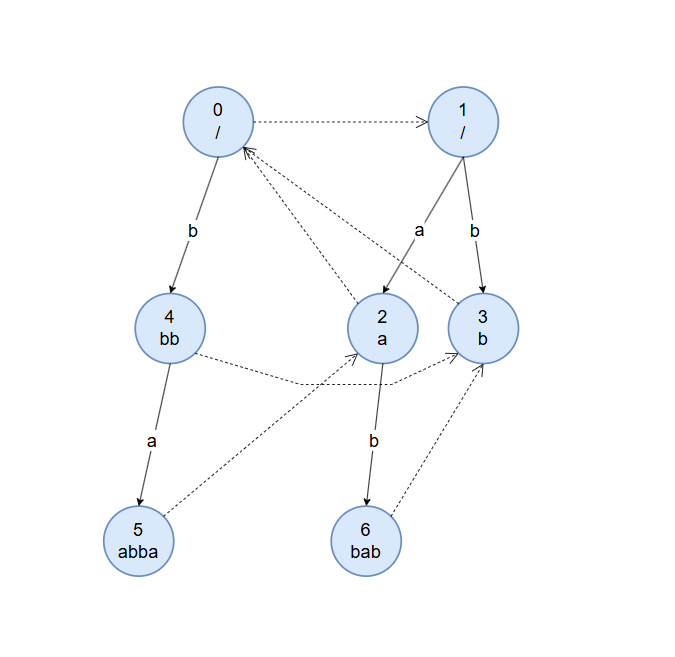
加入第六个字符 $c$ 。从节点 $6$ 开始匹配,到奇根满足 $s[i]=s[i-len[u]-1]$ ,其字符 $c$ 转移边未指向节点,建新节点 $7$ ,奇根的字符 $c$ 转移边指向节点 $7$ ,同时节点 $6$ 的 fail 指针指向偶根。
例题
我们构建回文自动机,提取出 fail 指针组成一棵树,由于 fail 指针指向的是最长的回文后缀,所以每个字符加入回文自动机后对应的节点在 fail 树上的深度就是这个字符结尾的回文子串个数。深度可以在线 $O(1)$ 维护。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 #include <bits/stdc++.h> #define FIO cin.tie(0); ios::sync_with_stdio(false) #define all(x) (x).begin(), (x).end() #define fi first #define se second #define TEST #define TESTS int t = 1; cin >> t; while (t--) #if 0 #define int i64 #define inf 0x3f3f3f3f3f3f3f3fLL #else #define inf 0x3f3f3f3f #endif using namespace std;using i64 = long long ;using u32 = unsigned ;using u64 = unsigned long long ;using pii = std::pair<int , int >;constexpr int N = 5e5 + 10 ;constexpr int MOD = 998244353 ;int fa[N], ch[N][26 ], len[N], d[N], idx, last;int s[N];void init () fa[0 ] = 1 ; len[1 ] = -1 ; idx = 1 ; last = 0 ; } int get_fail (int u, int i) while (i - len[u] - 1 <= 0 || s[i - len[u] - 1 ] != s[i]) { u = fa[u]; } return u; } int insert (int c, int i) int u = get_fail (last, i); if (!ch[u][c]) { int v = ++idx; fa[v] = ch[get_fail (fa[u], i)][c]; ch[u][c] = v; len[v] = len[u] + 2 ; d[v] = d[fa[v]] + 1 ; } last = ch[u][c]; return d[last]; } void solve () string ss; cin >> ss; int n = ss.size (); init (); for (int i = 1 , last = 0 ; i <= n; ++i) { s[i] = ((ss[i - 1 ] - 97 + last) % 26 + 26 ) % 26 ; last = insert (s[i], i); cout << last << " " ; } } signed main () FIO; TEST { solve (); } return 0 ; }
建立回文自动机,每次在当前字符结尾的最长回文子串的节点上记录出现次数+1,整个自动机建立完毕后,由于 fail 指针指向的是最长的回文后缀,那么当前节点出现出现多少次,fail 指针指向的节点也会额外出现多少次。按照逆拓扑序维护次数,同时计算答案即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 #include <bits/stdc++.h> #define FIO cin.tie(0); ios::sync_with_stdio(false) #define all(x) (x).begin(), (x).end() #define fi first #define se second #define TEST #define TESTS int t = 1; cin >> t; while (t--) #if 0 #define int i64 #define inf 0x3f3f3f3f3f3f3f3fLL #else #define inf 0x3f3f3f3f #endif using namespace std;using i64 = long long ;using u32 = unsigned ;using u64 = unsigned long long ;using pii = std::pair<int , int >constexpr int N = 2e5 + 10 ;constexpr int MOD = 998244353 ;void solve () string s; cin >> s; int n = s.size (); vector<int > fa (n + 10 ) , len (n + 10 ) , cnt (n + 10 ) ; vector<array<int , 26>> ch (n + 10 ); int tot = 1 , last = 0 ; fa[0 ] = 1 ; len[1 ] = -1 ; auto get_fail = [&](int u, int i) -> int { while (i - len[u] - 1 <= -1 || s[i - len[u] - 1 ] != s[i]) u = fa[u]; return u; }; auto insert = [&](int c, int i) -> void { int u = get_fail (last, i); if (!ch[u][c]) { fa[++tot] = ch[get_fail (fa[u], i)][c]; ch[u][c] = tot; len[tot] = len[u] + 2 ; } last = ch[u][c]; cnt[last]++; }; for (int i = 0 ; i < n; ++i) insert (s[i] - 'a' , i); i64 ans = 0 ; for (int i = tot; i >= 2 ; --i) { cnt[fa[i]] += cnt[i]; chkmax (ans, 1LL * len[i] * cnt[i]); } cout << ans << "\n" ; } signed main () FIO; TEST { solve (); } return 0 ; }
给定一个长度为 $n$ 的字符串 $S$ ,计算有多少个三元组 $(l,d,r)$,$1\le l \le d \le r$,使得 $S[l,d]$,$S[d+1,r]$,$S[l,r]$ 均是回文串。
建立回文自动机,我们可以得到每个本质不同回文子串 $S$ 的最长回文后缀的长度,因此可以得到回文子串的最小周期 $p$ 。如果周期是回文子串的因数,那么这个回文串 $S$ 可以看做是由另一个回文串 $S’$ 重复 $\frac{len[len]}{p}$ 次得到的,那么对于回文串 $S$ 就有 $\frac{len[len]}{p} - 1$ 种分割方式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 #include <bits/stdc++.h> #define FIO cin.tie(0); ios::sync_with_stdio(false) #define all(x) (x).begin(), (x).end() #define fi first #define se second #define TEST #define TESTS int t = 1; cin >> t; while (t--) #if 0 #define int i64 #define inf 0x3f3f3f3f3f3f3f3fLL #else #define inf 0x3f3f3f3f #endif using namespace std;using i64 = long long ;using u32 = unsigned ;using u64 = unsigned long long ;using pii = std::pair<int , int >;constexpr int N = 2e5 + 10 ;constexpr int MOD = 998244353 ;void solve () int n; cin >> n; string s; cin >> s; vector<int > fa (n + 10 ) , len (n + 10 ) , cnt (n + 10 ) ; vector<array<int , 26>> ch (n + 10 ); int idx = 1 , last = 0 ; fa[0 ] = 1 ; len[1 ] = -1 ; auto get = [&](int u, int i) -> int { while (i - len[u] - 1 <= -1 || s[i - len[u] - 1 ] != s[i]) u = fa[u]; return u; }; auto insert = [&](int c, int i) -> void { int u = get (last, i); if (!ch[u][c]) { fa[++idx] = ch[get (fa[u], i)][c]; ch[u][c] = idx; len[idx] = len[u] + 2 ; } last = ch[u][c]; cnt[last]++; }; for (int i = 0 ; i < n; ++i) insert (s[i] - 'a' , i); for (int i = idx; i >= 2 ; --i) cnt[fa[i]] += cnt[i]; i64 ans = 0 ; for (int i = 2 ; i <= idx; ++i) { int d = len[i] - len[fa[i]]; if (len[i] % d) continue ; ans += 1LL * (len[i] / d - 1 ) * cnt[i]; } cout << ans << "\n" ; } signed main () FIO; TEST { solve (); } return 0 ; }
求字符串的最长的由两个回文串拼接得到的子串的长度。
考虑枚举每一个分割点,那么自然的想法就是计算每个字符开头和结尾的最长回文子串长度。结尾的最长回文子串长度使用回文自动机易求,开头的最长回文子串长度再对反串建立回文自动机即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 #include <bits/stdc++.h> #define FIO cin.tie(0); ios::sync_with_stdio(false) #define all(x) (x).begin(), (x).end() #define fi first #define se second #define TEST #define TESTS int t = 1; cin >> t; while (t--) #if 0 #define int i64 #define inf 0x3f3f3f3f3f3f3f3fLL #else #define inf 0x3f3f3f3f #endif using namespace std;using i64 = long long ;using u32 = unsigned ;using u64 = unsigned long long ;using pii = std::pair<int , int >;constexpr int N = 1e5 + 10 ;constexpr int MOD = 998244353 ;struct PAM { int fa[N], ch[N][26 ], len[N], d[N], idx, last; int s[N]; void init () fa[0 ] = 1 ; len[1 ] = -1 ; idx = 1 ; last = 0 ; } int get_fail (int u, int i) while (i - len[u] - 1 <= 0 || s[i - len[u] - 1 ] != s[i]) { u = fa[u]; } return u; } int insert (int c, int i) int u = get_fail (last, i); if (!ch[u][c]) { int v = ++idx; fa[v] = ch[get_fail (fa[u], i)][c]; ch[u][c] = v; len[v] = len[u] + 2 ; d[v] = d[fa[v]] + 1 ; } last = ch[u][c]; return len[last]; } } p1, p2; int L[N], R[N];void solve () string s; cin >> s; int n = s.size (); p1.init (); p2.init (); for (int i = 1 ; i <= n; ++i) { p1.s[i] = s[i - 1 ] - 'a' ; p2.s[i] = s[n - i] - 'a' ; } for (int i = 1 ; i <= n; ++i) R[i] = p1.insert (p1.s[i], i); for (int i = 1 ; i <= n; ++i) L[n + 1 - i] = p2.insert (p2.s[i], i); int ans = 0 ; for (int i = 1 ; i < n; ++i) chkmax (ans, R[i] + L[i + 1 ]); cout << ans << "\n" ; } signed main () FIO; TEST { solve (); } return 0 ; }
求字符串的最长的形如 $ww^{R}ww^{R}$ 的子串的长度。
有了牛客那道D题,这题就是小case。依旧计算每个本质不同回文子串的最小周期 $d$ 。题目所述字符串长度显然是 $4$ 的倍数,同时需要被 $d$ 整除。但显然如果是某个串重复奇数次仍然不满足条件,因此需要被 $2d$ 整除,综上,$len[u] \equiv 0 \mod{lcm(4,2d)}$ 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 #include <bits/stdc++.h> #define FIO cin.tie(0); ios::sync_with_stdio(false) #define all(x) (x).begin(), (x).end() #define fi first #define se second #define TEST #define TESTS int t = 1; cin >> t; while (t--) #if 0 #define int i64 #define inf 0x3f3f3f3f3f3f3f3fLL #else #define inf 0x3f3f3f3f #endif using namespace std;using i64 = long long ;using u32 = unsigned ;using u64 = unsigned long long ;using pii = std::pair<int , int >;template <typename T> void chkmin (T& a, T b) min (a, b); }template <typename T> void chkmax (T& a, T b) max (a, b); }constexpr int N = 2e5 + 10 ;constexpr int MOD = 998244353 ;void solve () int n; cin >> n; string s; cin >> s; vector<int > fa (n + 2 ) , len (n + 2 ) ; vector<array<int , 26>> ch (n + 2 ); int idx = 1 , last = 0 ; fa[0 ] = 1 ; len[1 ] = -1 ; auto getfail = [&](int u, int i) -> int { while (i - len[u] - 1 <= -1 || s[i - len[u] - 1 ] != s[i]) u = fa[u]; return u; }; auto insert = [&](int c, int i) -> void { int u = getfail (last, i); if (!ch[u][c]) { fa[++idx] = ch[getfail (fa[u], i)][c]; ch[u][c] = idx; len[idx] = len[u] + 2 ; } last = ch[u][c]; }; for (int i = 0 ; i < n; ++i) insert (s[i] - 'a' , i); int ans = 0 ; for (int i = 2 ; i <= idx; ++i) { int d = len[i] - len[fa[i]]; if (len[i] % d || len[i] % 4 ) continue ; if (len[i] / d % 2 == 0 ) { chkmax (ans, len[i]); } } cout << ans << "\n" ; } signed main () FIO; TEST { solve (); } return 0 ; }
给定 $A$ , $B$ 两个字符串,统计满足 $1\le i \le j \le |A|$ , $1\le x \le y \le |b|$ ,$A[i,j]=B[x,y]$ 为回文串的 $(i,j,x,y)$ 四元组个数。
对两个字符串构建回文自动机,维护每个串出现的次数。从根节点开始同时 dfs ,由相同状态出发,如果同时存在某条转移边,显然也可以转移到相同的状态,所以对奇根和偶根做两次 dfs 统计答案即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 #include <bits/stdc++.h> #define FIO cin.tie(0); ios::sync_with_stdio(false) #define all(x) (x).begin(), (x).end() #define fi first #define se second #define TEST #define TESTS int t = 1; cin >> t; while (t--) #if 0 #define int i64 #define inf 0x3f3f3f3f3f3f3f3fLL #else #define inf 0x3f3f3f3f #endif using namespace std;using i64 = long long ;using u32 = unsigned ;using u64 = unsigned long long ;using pii = std::pair<int , int >;constexpr int N = 5e4 + 10 ;constexpr int MOD = 998244353 ;struct PAM { int n, idx, lst; vector<int > fa, len, cnt; vector<array<int , 26>> ch; string_view s; void init (string_view _s) s = _s; n = s.size (); fa.assign (n + 2 , {}); len.assign (n + 2 , {}); cnt.assign (n + 2 , {}); ch.assign (n + 2 , {}); idx = 1 ; lst = 0 ; fa[0 ] = 1 ; len[1 ] = -1 ; } int getfail (int u, int i) while (i - len[u] - 1 <= -1 || s[i - len[u] - 1 ] != s[i]) u = fa[u]; return u; } void insert (int c, int i) int u = getfail (lst, i); if (!ch[u][c]) { fa[++idx] = ch[getfail (fa[u], i)][c]; ch[u][c] = idx; len[idx] = len[u] + 2 ; } lst = ch[u][c]; cnt[lst]++; } void build () for (int i = 0 ; i < n; ++i) insert (s[i] - 'A' , i); for (int i = idx; i >= 2 ; --i) cnt[fa[i]] += cnt[i]; cnt[0 ] = cnt[1 ] = 0 ; } } P, Q; void solve () string s1, s2; cin >> s1 >> s2; int n = s1.size (), m = s2.size (); P.init (s1), Q.init (s2); P.build (), Q.build (); i64 ans = 0 ; auto dfs = [&](auto && dfs, int x, int y) -> void { ans += 1LL * P.cnt[x] * Q.cnt[y]; for (int i = 0 ; i < 26 ; ++i) { if (P.ch[x][i] && Q.ch[y][i]) dfs (dfs, P.ch[x][i], Q.ch[y][i]); } }; dfs (dfs, 1 , 1 ); dfs (dfs, 0 , 0 ); cout << ans << "\n" ; } signed main () FIO; solve (); return 0 ; }
给定字符串 $A$、$B$,计算同时在 $A$ 和 $B$ 中出现过的最长的本质不同回文子串的数量。
可以按照上一道题的做法建两个回文自动机同时 DFS。这道题每个串最多产生 $1$ 的贡献,也可以直接建 $A + B$ 的回文自动机,维护两个串加入后在回文自动机上的节点的集合,集合的交集就是所有同时出现的回文子串。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 #include <bits/stdc++.h> #define FIO cin.tie(0); ios::sync_with_stdio(false) #define all(x) (x).begin(), (x).end() #define fi first #define se second #define TEST #define TESTS int t = 1; cin >> t; while (t--) #if 0 #define int i64 #define inf 0x3f3f3f3f3f3f3f3fLL #else #define inf 0x3f3f3f3f #endif using namespace std;using i64 = long long ;using u32 = unsigned ;using u64 = unsigned long long ;using pii = std::pair<int , int >;constexpr int N = 2e5 + 10 ;constexpr int MOD = 998244353 ;void solve () int n, m; cin >> n >> m; string s1, s2, s; cin >> s1 >> s2; s = s1 + "$#" + s2; int L = s.size (); vector<int > fa (L + 2 ) , len (L + 2 ) ; vector<array<int , 26>> ch (L + 2 ); fa[0 ] = 1 ; len[1 ] = -1 ; int idx = 1 , lst = 0 ; auto getfail = [&](int u, int i) -> int { while (i - len[u] - 1 <= -1 || s[i - len[u] - 1 ] != s[i]) u = fa[u]; return u; }; auto insert = [&](int c, int i) -> int { int u = getfail (lst, i); if (!ch[u][c]) { fa[++idx] = ch[getfail (fa[u], i)][c]; ch[u][c] = idx; len[idx] = len[u] + 2 ; } lst = ch[u][c]; return lst; }; set<int > st, st2; for (int i = 0 ; i < n; ++i) { st.insert (insert (s[i] - 'a' , i)); } lst = 0 ; for (int i = n + 2 ; i < L; ++i) { st2.insert (insert (s[i] - 'a' , i)); } int ans = 0 , cnt = 0 ; for (int x : st2) { if (st.contains (x)) { if (len[x] > ans) { ans = len[x]; cnt = 1 ; } else if (len[x] == ans) { cnt++; } } } cout << ans << " " << cnt << "\n" ; } signed main () FIO; solve (); return 0 ; }
给定一个长度为偶数的字符串 $S$ ,要求将 $S$ 划分为 $t_{1},t_{2},\cdots,t_{k}$,其中 $k$ 是偶数且 $t_i=t_{k-i+1}$,求划分方案数。
构建字符串 $T=S[1]S[n]S[2]S[n-1]\cdots S[\frac{n}{2}-1]S[\frac{n}{2}]$ ,问题等价于求 $T$ 的偶回文划分方案数。
考虑动态规划,记 $dp[i]$ 表示 $T$ 长度为 $i$ 的前缀的偶回文划分方案数,易得转移方程 $dp[i]=\sum\limits_{s[j+1,i]为回文串}dp[j],(i \equiv 0 \mod{2})$ 。初始状态 $dp[0]=1$ 。朴素转移是 $O(n^2)$ 的,需要进行优化。
根据border理论,可以证明字符串 $S$ 的所有回文后缀按照长度排序后,可以划分成 $\log{|S|}$ 段等差数列。因此我们每次跳一段,把信息维护在每段等差数列的最长的那个节点上,就可以单次做 $O(\log{n})$ 的转移,整体时间复杂度优化至 $O(n\log{n})$ 。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 #include <bits/stdc++.h> #define FIO cin.tie(0); ios::sync_with_stdio(false) #define all(x) (x).begin(), (x).end() #define fi first #define se second #define TEST #define TESTS int t = 1; cin >> t; while (t--) #if 0 #define int i64 #define inf 0x3f3f3f3f3f3f3f3fLL #else #define inf 0x3f3f3f3f #endif using namespace std;using i64 = long long ;using u32 = unsigned ;using u64 = unsigned long long ;using pii = std::pair<int , int >;constexpr int N = 2e5 + 10 ;constexpr int MOD = 1e9 + 7 ;void solve () string t, s; cin >> t; int n = t.size (); s = t; for (int i = 0 , j = 0 ; j < n; ++i) s[j++] = t[i], s[j++] = t[n - 1 - i]; vector<int > fa (n + 20 ) , len (n + 20 ) , dif (n + 20 ) , slink (n + 20 ) ; vector<array<int , 26>> ch (n + 20 ); int idx = 1 , lst = 0 ; fa[0 ] = 1 , len[1 ] = -1 ; auto getfail = [&](int u, int i) -> int { while (s[i - len[u] - 1 ] != s[i]) u = fa[u]; return u; }; auto insert = [&](int c, int i) -> void { int u = getfail (lst, i); if (!ch[u][c]) { fa[++idx] = ch[getfail (fa[u], i)][c]; ch[u][c] = idx; len[idx] = len[u] + 2 ; dif[idx] = len[idx] - len[fa[idx]]; if (dif[idx] == dif[fa[idx]]) slink[idx] = slink[fa[idx]]; else slink[idx] = fa[idx]; } lst = ch[u][c]; }; vector<int > dp (n + 1 ) , g (n + 20 ) ; dp[0 ] = 1 ; for (int i = 1 ; i <= n; ++i) { insert (s[i - 1 ] - 'a' , i - 1 ); for (int x = lst; x > 1 ; x = slink[x]) { g[x] = dp[i - len[slink[x]] - dif[x]]; if (dif[x] == dif[fa[x]]) g[x] = (g[x] + g[fa[x]]) % MOD; if (i % 2 == 0 ) dp[i] = (dp[i] + g[x]) % MOD; } } cout << dp[n] << "\n" ; } signed main () FIO; solve (); return 0 ; }
结语 这篇笔记加了很多图。亲身体会证明了按照算法流程模拟一遍对理解算法细节有极大的帮助,尤其数据结构和图论,好脑子不如烂笔头(
常有人调侃字符串题就是哈希+二分(笔者自己也在内),但是调侃归调侃,也没办法断言这些算法就是useless。笔者认为,自动机作为一种特化的数据结构,它针对某类问题的处理能力真的令人惊叹。这么妙的算法,有什么理由不去学呢?
参考资料 OIWiki - 回文树
回文自动机(PAM) 详解